Clustergram#
Visualization and diagnostics for cluster analysis#
Clustergram is a diagram proposed by Matthias Schonlau in his paper The clustergram: A graph for visualizing hierarchical and nonhierarchical cluster analyses:
In hierarchical cluster analysis, dendrograms are used to visualize how clusters are formed. I propose an alternative graph called a “clustergram” to examine how cluster members are assigned to clusters as the number of clusters increases. This graph is useful in exploratory analysis for nonhierarchical clustering algorithms such as k-means and for hierarchical cluster algorithms when the number of observations is large enough to make dendrograms impractical.
The clustergram was later implemented in R by Tal Galili, who also gives a thorough explanation of the concept.
This is a Python implementation, originally based on Tal’s script, written for
scikit-learn and RAPIDS cuML implementations of K-Means, Mini Batch K-Means and
Gaussian Mixture Model (scikit-learn only) clustering, plus hierarchical/agglomerative
clustering using SciPy. Alternatively, you can create clustergram using from_*
constructors based on alternative clustering algorithms.
![]()
Getting started#
You can install clustergram from conda or pip:
conda install clustergram -c conda-forge
pip install clustergram
In any case, you still need to install your selected backend (scikit-learn and scipy
or cuML).
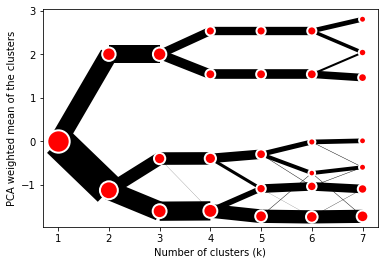
The example of clustergram on Palmer penguins dataset:
import seaborn
df = seaborn.load_dataset('penguins')
First we have to select numerical data and scale them.
from sklearn.preprocessing import scale
data = scale(df.drop(columns=['species', 'island', 'sex']).dropna())
And then we can simply pass the data to clustergram.
from clustergram import Clustergram
cgram = Clustergram(range(1, 8))
cgram.fit(data)
cgram.plot()
References#
Schonlau M. The clustergram: a graph for visualizing hierarchical and non-hierarchical cluster analyses. The Stata Journal, 2002; 2 (4):391-402.
Schonlau M. Visualizing Hierarchical and Non-Hierarchical Cluster Analyses with Clustergrams. Computational Statistics: 2004; 19(1):95-111.